How to write an afl wrapper for any language
08 Jul 2019
Do you want to use afl to fuzz a program written in a language other than C or C++? Is this language neither python, go, nor ruby, for which experimental afl wrappers are already available? Do you therefore want to write your own experimental afl wrapper for your language, resulting in a project that will almost certainly be entirely novel, unique, and worthy of a GitHub repo and a README?
Excellent.
This post will show you how to write an afl wrapper for your language from scratch. It shouldn’t take much more than 250 lines of code, and writing it will teach you a lot about both afl and yourself. When you’re done you’ll be able to fuzz programs written in your chosen language; and who knows, you might even find a bug or two.
Overview
We are going to write a wrapper for afl’s deferred forkserver mode, which is described in detail in the afl docs. Implementing persistent mode (also described in the docs) is left as an extension exercise for the reader.
Our wrapper will allow us to write fuzz harnesses (programs that exercise your code in a fuzz-friendly way) that look something like this:
do_time_consuming_initialization()
# afl_init is the equivalent of afl's
# __AFL_INIT method. It sets the point
# at which the harness should start
# forking off children, saving them
# from each having to run
# do_time_consuming_initialization.
#
# TODO: write the afl_init method
afl_init()
run_a_test_case()
We can then run afl-fuzz on our harness as normal:
# Ruby example:
afl-fuzz \
-i work/input \
-o work/output \
-- /path/to/ruby harness.rb
The project of writing our afl wrapper will be composed of two tasks. The first will be to implement the afl_init function spiked in the pseudo-code above. This function will need to mimic the functionality of afl’s __AFL_INIT:
- Initialize the shared memory segment that our program will share with afl
- Loop forever, forking off child processes that run test cases by executing the rest of the fuzz harness
- Report the exit statuses of these child processes to the forkserver
This function will therefore look something like the following pseudo-code:
def afl_init()
# Initialize the memory segment that our
# program shares with afl
init_shm()
# Initialize and ensure that we can
# communicate with afl's forkserver.
init_forkserver()
# Loop the parent process forever,
# forking off child processes and
# reporting their outcomes to afl.
while True do
# Drain the forkserver's output in
# order to indicate to afl that we
# are about to run another test case.
forkserver_read()
# Fork a child process. In the new
# child process, child_pid will be
# set to nil. In the parent, it will
# be set to the pid of the child.
child_pid = fork
# If child_pid is nil then we are
# the child process, so we return
# from `afl_init` and run a test
# case by executing the rest of the
# harness.
break if child_pid == nil
# If child_pid is not nil then we
# are the parent, so our job is to
# monitor and report the status of
# the child.
#
# First we write child_pid to the
# afl forkserver.
forkserver_write(child_pid)
# Then we wait for the child process
# to finish and record its status.
status = waitpid2(child_pid)
# Finally we report this status to
# afl so that it knows if the test
# case resulted in a crash or not.
forkserver_write(status)
# Now that the child process has
# finished, we (the parent) go back
# to the top of the loop in order
# to fork another child and run
# another test case.
end
# Close the forksrv file descriptors.
# This line will only ever be reached
# by the child process.
close_forksrv_fds()
end
Once we have implemented afl_init, our second task will be to add instrumentation. This instrumentation will write information about our harness program’s execution path to the shared memory segment that we initialized in afl_init. This is usually the job of afl-clang and afl’s other special C and C++ compilers, but we’re working with <insert your language here> so those are of no use to us. Afl uses instrumentation information to deduce how your program’s execution path is affected by the test cases it feeds it.
Let’s look at how afl and afl-ruby tackle the challenges of managing the forkserver and execution path instrumentation, and how we can tackle them in your language too.
0. Patch afl
Before we start, we will probably need to patch afl itself. Afl performs several sanity checks on the target program it is given, many of which were written with the assumption that it would only ever be run against C or C++ programs. Try running afl against an arbitrary program written in your language:
# PHP example:
afl-fuzz \
-i work/input \
-o work/output \
-- /path/to/php test.php
You will probably see an error like No instrumentation detected. Unfortunately for us, afl checks for instrumentation by searching through the contents of its target binary program (in this example, the PHP intepreter) for a magic string. This check will be difficult for us to pass, and the easiest way for us to get around it will be to edit and rebuild afl itself to comment it out. Afl-ruby has a git patch that you can download and git apply, or you can make the change yourself in your text editor:
git clone [email protected]:mirrorer/afl.git
cd ./afl
git checkout -b comment-out-checks
# ...edit and comment out afl checks as needed...
git commit -m "Comment out target checks"
make install
# Check that this did indeed update your
# AFL - the output should be to the
# `afl-fuzz` binary in the current dir.
ls -la $(which afl-fuzz)
You may find more checks that keep tripping you up. Try to find a reasonable and elegant workaround if you can, but if you can’t then you can comment them out too.
You can leave this step until later if you prefer.
1. Initialize afl’s shared memory
We’ll start by attaching our program to afl’s shared memory segment. This is where afl expects us to write information about our program’s execution path.
First, we will get the segment’s address in memory. Afl writes this address to the __AFL_SHM_ID environment variable, which we should be able to read without any trouble. Next, once we have the segment’s address, we can use the shmat syscall to attach it to our program’s memory space. Finally, we will store the address returned by shmat in a variable so that we can use it later to write execution path data to the shared memory segment.
Here’s how afl does this:
#define SHM_ENV_VAR "__AFL_SHM_ID"
static void __afl_map_shm(void) {
u8 *id_str = getenv(SHM_ENV_VAR);
if (id_str) {
u32 shm_id = atoi(id_str);
__afl_area_ptr = shmat(shm_id, NULL, 0);
if (__afl_area_ptr == (void *)-1) _exit(1);
/* Write something into the bitmap so
that even with low AFL_INST_RATIO,
our parent doesn't give up on us. */
__afl_area_ptr[0] = 1;
}
}
(GitHub)
Afl-ruby does something very similar:
static const char* SHM_ENV_VAR = "__AFL_SHM_ID";
VALUE afl__init_shm(void) {
VALUE exc = rb_const_get(
AFL,
rb_intern("RuntimeError"));
if (init_done == Qtrue) {
rb_raise(exc, "AFL already initialized");
}
const char * afl_shm_id_str = getenv(SHM_ENV_VAR);
if (afl_shm_id_str == NULL) {
rb_raise(
exc,
"No AFL SHM segment specified. AFL's"
"SHM env var is not set. Are we "
"actually running inside AFL?");
}
const int afl_shm_id = atoi(afl_shm_id_str);
afl_area = shmat(afl_shm_id, NULL, 0);
if (afl_area == (void*) -1) {
rb_raise(exc, "Couldn't map shm segment");
}
init_done = Qtrue;
return Qtrue;
}
(GitHub)
Try to replicate this functionality in your language.
2. Communicate with afl’s forkserver
Next we need to set up our communication with afl’s forkserver. We need to be able to inform afl:
- When a new test case is about to run
- When a test case has finished running
- Whether a completed test case resulted in a crash or not
In afl’s deferred forkserver mode, our main process doesn’t run test cases. Instead, our main process’s job is to spawn and manage child processes, and it is these that actually run test cases. Our main, parent process should run in an infinite loop, and with each pass it should fork off a new child process, wait for the child to run a test case, and report the child’s exit status to afl.
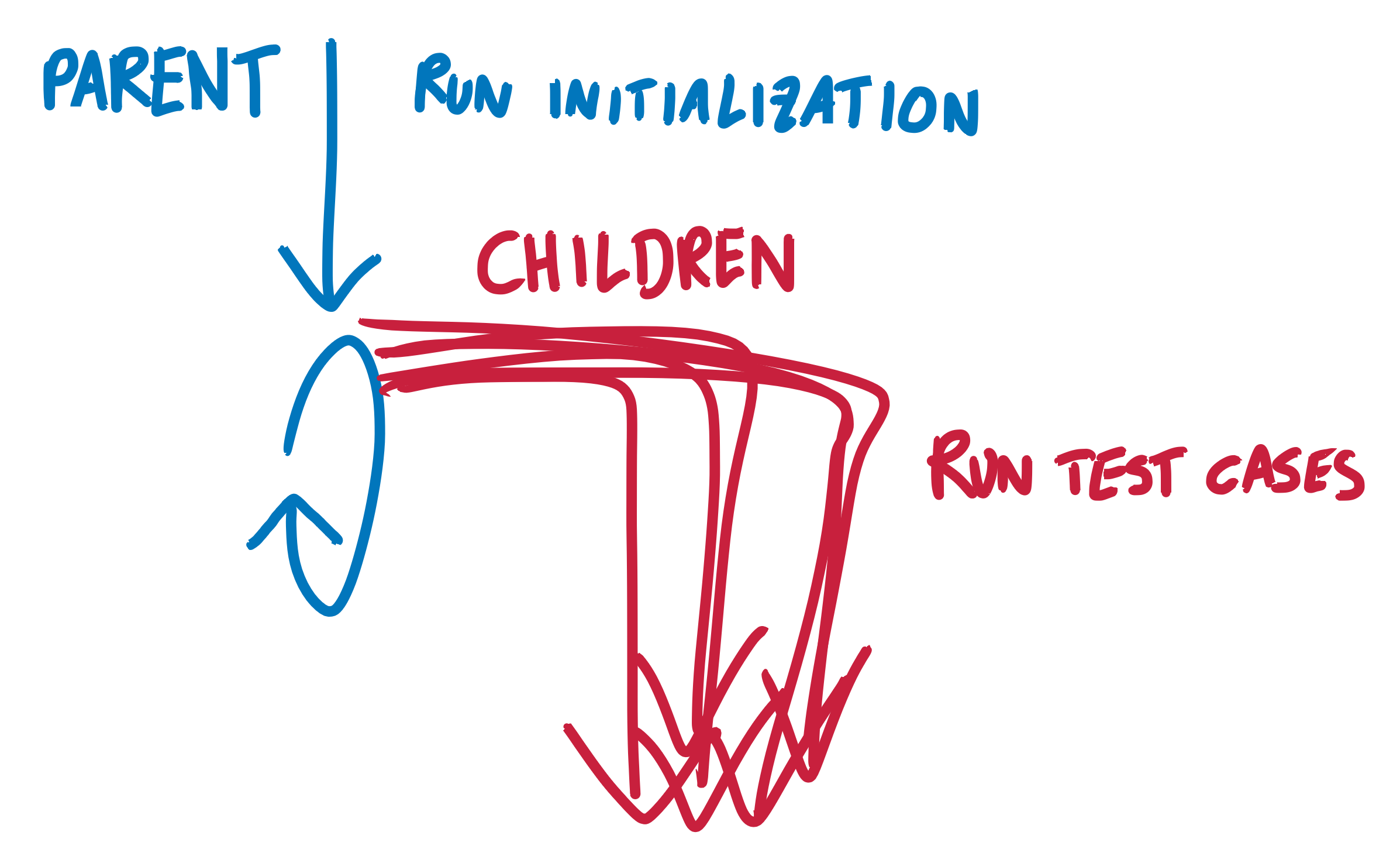
Here’s the pseudo-code from the introduction, reproduced without the comments:
def afl_init()
init_shm()
init_forkserver()
while True do
forkserver_read()
child_pid = fork
break if child_pid == nil
forkserver_write(child_pid)
status = waitpid2(child_pid)
forkserver_write(status)
end
close_forksrv_fds()
end
Testing forkserver writes
We will communicate with the afl forkserver over two pipes with file descriptors of 198 and 199 (these values are hardcoded by afl). Afl specifies that the 198 pipe is for reading data from the forkserver, and 199 is for writing to it.
At the start of its afl_init method, afl checks that the forkserver-write pipe is working by writing 4 null bytes to the pipe and bailing if anything goes wrong.
#define FORKSRV_FD 198
// ...lots of other stuff..
if (write(FORKSRV_FD + 1, tmp, 4) != 4) return;
(GitHub)
Afl-ruby does the same thing:
static const int FORKSRV_FD = 198;
VALUE afl__init_forkserver(void) {
int ret = write(FORKSRV_FD + 1, "\0\0\0\0", 4);
if (ret != 4) {
VALUE exc = rb_const_get(
AFL,
rb_intern("RuntimeError"));
rb_raise(exc, "Couldn't write to forksrv");
}
return Qnil;
}
(GitHub)
Try to replicate this functionality in your language too.
Forking new processes
We will fork child processes using the fork syscall (or your language’s wrapper around it). This call creates a new child process that is an almost-exact copy of its parent. The only material difference between parent and child is that in the child the call to fork returns 0, whereas in the parent it returns the new child’s process ID.
We can use this difference to distinguish between parent and child processes:
child_pid = fork
if child_pid == 0 {
do_child_stuff()
} else {
do_parent_stuff()
}
We will have our child break out of its parent’s fork-loop and continue through the rest of our harness, where it will run a single test case before exiting. Meanwhile the parent will wait for the child to exit, report the child’s exit status to the afl forkserver, then go back to the top of the loop to fork off a new child and do it all again.
In afl-ruby the forkserver functionality is implemented like so:
def self.spawn_child
loop do
# Read and discard the previous test's
# status. We don't care about the value,
# but if we don't read it, the fork
# server eventually blocks, and then we
# block on the call to _forkserver_write
# below.
self._forkserver_read
# Fork a child process
child_pid = fork
# If we are the child thread, return
# back to the main program and actually
# run a testcase.
#
# If we are the parent, we are the
# forkserver and we should continue in
# this loop so we can fork another child
# once this one has returned.
return if child_pid.nil?
# Write child's thread's pid to AFL's
# fork server
self._forkserver_write(child_pid)
# Wait for the child to return
_pid, status = Process.waitpid2(child_pid)
# Report the child's exit status to the
# AFL forkserver
report_status = status.termsig || status.exitstatus
self._forkserver_write(report_status)
end
end
(GitHub)
In afl this code is a little interwoven with other features, but you can still read the source.
Re-implement the fork-loop in your language.
3. Write execution path information to shared memory
The story so far:
- We’ve initialized and attached to afl’s shared memory segment
- Afl and our target program are successfully communicating with each other via two pipes
- A single parent process is infinite looping and repeatedly forking off new child processes that run test cases
All that remains is for us to write information about our program’s execution path to afl’s shared memory segment. Afl can then use this information to intelligently select new, interesting test cases.
To get and report information about our program’s execution path, we will need to hook into your language’s interpreter or compiler. How we do this will depend on what tools your language provides. For example:
- afl’s llvm mode augments the C compiler with an llvm pass
- afl-ruby uses a
trace function that gets called by the Ruby interpreter every time a new function is entered
- python-afl uses another
trace function that is attached to the Python interpreter with sys.settrace
If you have the choice then it will probably be easier to add runtime hooks to your language’s interpreter than to modify its compiler, but you should feel happy using any approach that is available.
We will use our hooks to write information about our program’s execution path to afl’s shared memory segment. We can’t explicitly record the filename and line number of every line of code that is executed, because this would quickly get intractable for a program with thousands of files and millions of lines. Instead, when an “interesting” line of code runs (more on which below), we will increment a counter at a memory address given by a simple function of the current and previously recorded files and line numbers. The resulting bitmap can’t be mapped back into an exact execution path, but afl can still use it to notice and interpret differences in execution paths between different test cases.
We may get some collisions - two different lines of code that map to the same memory location and increment the same counter. But afl’s claim and bet is that as long as there aren’t too many of them, these collisions won’t materially impact its efficacy.
It may prove useful to even further reduce the amount of data that we send to afl. Writing to the shared memory takes CPU time, and writing too much data can flood the shared memory and make it hard for afl to extract any useful signals. There are at least two ways to deal with this. We can sample our instrumentation, and only report information for a random X% of executed lines. This is what afl does. Or, if your language provides the necessary tools, we can only write information for a subset of particularly interesting lines - for example, function calls or returns. This is what afl-ruby does.
It will be hard to rigorously verify that the interaction between your program and afl is exactly correct. Afl is not very amenable to unit testing. However, there are two heuristics you can use to convince yourself that your code is right. First, afl will yell at you if you try to fuzz something that doesn’t have any instrumentation. If afl is happy to start fuzzing your program then you must at least be writing something to the shared memory. And second, if your instrumentation is helpful to afl then you should be able to find a bug in a trivial example target much quicker than in QEMU (uninstrumented) mode.
Putting it all together
You should now have a working afl wrapper for your language. Try it out on a trivial test harness containing a simple bug, like the example in the afl-ruby README. You should see afl detect new execution paths and quickly find the crash. When you’re convinced that everything is working, point afl at the program that you originally wanted to fuzz (several hours and hundreds of lines of code ago). Whilst you’re waiting for afl to serve you up some bugs you can tidy up your wrapper code, write some docs, and push everything to GitHub or Bitbucket. If you have the momentum, look into and consider implementing ancillary afl tools like afl-cov, afl-cmin, and persistent mode.
You’re done. Congratulations!
Do you want to use afl to fuzz a program written in a language other than C or C++? Is this language neither python, go, nor ruby, for which experimental afl wrappers are already available? Do you therefore want to write your own experimental afl wrapper for your language, resulting in a project that will almost certainly be entirely novel, unique, and worthy of a GitHub repo and a README?
Excellent.
This post will show you how to write an afl wrapper for your language from scratch. It shouldn’t take much more than 250 lines of code, and writing it will teach you a lot about both afl and yourself. When you’re done you’ll be able to fuzz programs written in your chosen language; and who knows, you might even find a bug or two.
Overview
We are going to write a wrapper for afl’s deferred forkserver mode, which is described in detail in the afl docs. Implementing persistent mode (also described in the docs) is left as an extension exercise for the reader.
Our wrapper will allow us to write fuzz harnesses (programs that exercise your code in a fuzz-friendly way) that look something like this:
do_time_consuming_initialization()
# afl_init is the equivalent of afl's
# __AFL_INIT method. It sets the point
# at which the harness should start
# forking off children, saving them
# from each having to run
# do_time_consuming_initialization.
#
# TODO: write the afl_init method
afl_init()
run_a_test_case()
We can then run afl-fuzz on our harness as normal:
# Ruby example:
afl-fuzz \
-i work/input \
-o work/output \
-- /path/to/ruby harness.rb
The project of writing our afl wrapper will be composed of two tasks. The first will be to implement the afl_init function spiked in the pseudo-code above. This function will need to mimic the functionality of afl’s __AFL_INIT:
- Initialize the shared memory segment that our program will share with afl
- Loop forever, forking off child processes that run test cases by executing the rest of the fuzz harness
- Report the exit statuses of these child processes to the forkserver
This function will therefore look something like the following pseudo-code:
def afl_init()
# Initialize the memory segment that our
# program shares with afl
init_shm()
# Initialize and ensure that we can
# communicate with afl's forkserver.
init_forkserver()
# Loop the parent process forever,
# forking off child processes and
# reporting their outcomes to afl.
while True do
# Drain the forkserver's output in
# order to indicate to afl that we
# are about to run another test case.
forkserver_read()
# Fork a child process. In the new
# child process, child_pid will be
# set to nil. In the parent, it will
# be set to the pid of the child.
child_pid = fork
# If child_pid is nil then we are
# the child process, so we return
# from `afl_init` and run a test
# case by executing the rest of the
# harness.
break if child_pid == nil
# If child_pid is not nil then we
# are the parent, so our job is to
# monitor and report the status of
# the child.
#
# First we write child_pid to the
# afl forkserver.
forkserver_write(child_pid)
# Then we wait for the child process
# to finish and record its status.
status = waitpid2(child_pid)
# Finally we report this status to
# afl so that it knows if the test
# case resulted in a crash or not.
forkserver_write(status)
# Now that the child process has
# finished, we (the parent) go back
# to the top of the loop in order
# to fork another child and run
# another test case.
end
# Close the forksrv file descriptors.
# This line will only ever be reached
# by the child process.
close_forksrv_fds()
end
Once we have implemented afl_init, our second task will be to add instrumentation. This instrumentation will write information about our harness program’s execution path to the shared memory segment that we initialized in afl_init. This is usually the job of afl-clang and afl’s other special C and C++ compilers, but we’re working with <insert your language here> so those are of no use to us. Afl uses instrumentation information to deduce how your program’s execution path is affected by the test cases it feeds it.
Let’s look at how afl and afl-ruby tackle the challenges of managing the forkserver and execution path instrumentation, and how we can tackle them in your language too.
0. Patch afl
Before we start, we will probably need to patch afl itself. Afl performs several sanity checks on the target program it is given, many of which were written with the assumption that it would only ever be run against C or C++ programs. Try running afl against an arbitrary program written in your language:
# PHP example:
afl-fuzz \
-i work/input \
-o work/output \
-- /path/to/php test.php
You will probably see an error like No instrumentation detected. Unfortunately for us, afl checks for instrumentation by searching through the contents of its target binary program (in this example, the PHP intepreter) for a magic string. This check will be difficult for us to pass, and the easiest way for us to get around it will be to edit and rebuild afl itself to comment it out. Afl-ruby has a git patch that you can download and git apply, or you can make the change yourself in your text editor:
git clone [email protected]:mirrorer/afl.git
cd ./afl
git checkout -b comment-out-checks
# ...edit and comment out afl checks as needed...
git commit -m "Comment out target checks"
make install
# Check that this did indeed update your
# AFL - the output should be to the
# `afl-fuzz` binary in the current dir.
ls -la $(which afl-fuzz)
You may find more checks that keep tripping you up. Try to find a reasonable and elegant workaround if you can, but if you can’t then you can comment them out too.
You can leave this step until later if you prefer.
1. Initialize afl’s shared memory
We’ll start by attaching our program to afl’s shared memory segment. This is where afl expects us to write information about our program’s execution path.
First, we will get the segment’s address in memory. Afl writes this address to the __AFL_SHM_ID environment variable, which we should be able to read without any trouble. Next, once we have the segment’s address, we can use the shmat syscall to attach it to our program’s memory space. Finally, we will store the address returned by shmat in a variable so that we can use it later to write execution path data to the shared memory segment.
Here’s how afl does this:
#define SHM_ENV_VAR "__AFL_SHM_ID"
static void __afl_map_shm(void) {
u8 *id_str = getenv(SHM_ENV_VAR);
if (id_str) {
u32 shm_id = atoi(id_str);
__afl_area_ptr = shmat(shm_id, NULL, 0);
if (__afl_area_ptr == (void *)-1) _exit(1);
/* Write something into the bitmap so
that even with low AFL_INST_RATIO,
our parent doesn't give up on us. */
__afl_area_ptr[0] = 1;
}
}
(GitHub)
Afl-ruby does something very similar:
static const char* SHM_ENV_VAR = "__AFL_SHM_ID";
VALUE afl__init_shm(void) {
VALUE exc = rb_const_get(
AFL,
rb_intern("RuntimeError"));
if (init_done == Qtrue) {
rb_raise(exc, "AFL already initialized");
}
const char * afl_shm_id_str = getenv(SHM_ENV_VAR);
if (afl_shm_id_str == NULL) {
rb_raise(
exc,
"No AFL SHM segment specified. AFL's"
"SHM env var is not set. Are we "
"actually running inside AFL?");
}
const int afl_shm_id = atoi(afl_shm_id_str);
afl_area = shmat(afl_shm_id, NULL, 0);
if (afl_area == (void*) -1) {
rb_raise(exc, "Couldn't map shm segment");
}
init_done = Qtrue;
return Qtrue;
}
(GitHub)
Try to replicate this functionality in your language.
2. Communicate with afl’s forkserver
Next we need to set up our communication with afl’s forkserver. We need to be able to inform afl:
- When a new test case is about to run
- When a test case has finished running
- Whether a completed test case resulted in a crash or not
In afl’s deferred forkserver mode, our main process doesn’t run test cases. Instead, our main process’s job is to spawn and manage child processes, and it is these that actually run test cases. Our main, parent process should run in an infinite loop, and with each pass it should fork off a new child process, wait for the child to run a test case, and report the child’s exit status to afl.
Here’s the pseudo-code from the introduction, reproduced without the comments:
def afl_init()
init_shm()
init_forkserver()
while True do
forkserver_read()
child_pid = fork
break if child_pid == nil
forkserver_write(child_pid)
status = waitpid2(child_pid)
forkserver_write(status)
end
close_forksrv_fds()
end
Testing forkserver writes
We will communicate with the afl forkserver over two pipes with file descriptors of 198 and 199 (these values are hardcoded by afl). Afl specifies that the 198 pipe is for reading data from the forkserver, and 199 is for writing to it.
At the start of its afl_init method, afl checks that the forkserver-write pipe is working by writing 4 null bytes to the pipe and bailing if anything goes wrong.
#define FORKSRV_FD 198
// ...lots of other stuff..
if (write(FORKSRV_FD + 1, tmp, 4) != 4) return;
(GitHub)
Afl-ruby does the same thing:
static const int FORKSRV_FD = 198;
VALUE afl__init_forkserver(void) {
int ret = write(FORKSRV_FD + 1, "\0\0\0\0", 4);
if (ret != 4) {
VALUE exc = rb_const_get(
AFL,
rb_intern("RuntimeError"));
rb_raise(exc, "Couldn't write to forksrv");
}
return Qnil;
}
(GitHub)
Try to replicate this functionality in your language too.
Forking new processes
We will fork child processes using the fork syscall (or your language’s wrapper around it). This call creates a new child process that is an almost-exact copy of its parent. The only material difference between parent and child is that in the child the call to fork returns 0, whereas in the parent it returns the new child’s process ID.
We can use this difference to distinguish between parent and child processes:
child_pid = fork
if child_pid == 0 {
do_child_stuff()
} else {
do_parent_stuff()
}
We will have our child break out of its parent’s fork-loop and continue through the rest of our harness, where it will run a single test case before exiting. Meanwhile the parent will wait for the child to exit, report the child’s exit status to the afl forkserver, then go back to the top of the loop to fork off a new child and do it all again.
In afl-ruby the forkserver functionality is implemented like so:
def self.spawn_child
loop do
# Read and discard the previous test's
# status. We don't care about the value,
# but if we don't read it, the fork
# server eventually blocks, and then we
# block on the call to _forkserver_write
# below.
self._forkserver_read
# Fork a child process
child_pid = fork
# If we are the child thread, return
# back to the main program and actually
# run a testcase.
#
# If we are the parent, we are the
# forkserver and we should continue in
# this loop so we can fork another child
# once this one has returned.
return if child_pid.nil?
# Write child's thread's pid to AFL's
# fork server
self._forkserver_write(child_pid)
# Wait for the child to return
_pid, status = Process.waitpid2(child_pid)
# Report the child's exit status to the
# AFL forkserver
report_status = status.termsig || status.exitstatus
self._forkserver_write(report_status)
end
end
(GitHub)
In afl this code is a little interwoven with other features, but you can still read the source.
Re-implement the fork-loop in your language.
3. Write execution path information to shared memory
The story so far:
- We’ve initialized and attached to afl’s shared memory segment
- Afl and our target program are successfully communicating with each other via two pipes
- A single parent process is infinite looping and repeatedly forking off new child processes that run test cases
All that remains is for us to write information about our program’s execution path to afl’s shared memory segment. Afl can then use this information to intelligently select new, interesting test cases.
To get and report information about our program’s execution path, we will need to hook into your language’s interpreter or compiler. How we do this will depend on what tools your language provides. For example:
- afl’s llvm mode augments the C compiler with an llvm pass
- afl-ruby uses a
tracefunction that gets called by the Ruby interpreter every time a new function is entered - python-afl uses another
tracefunction that is attached to the Python interpreter withsys.settrace
If you have the choice then it will probably be easier to add runtime hooks to your language’s interpreter than to modify its compiler, but you should feel happy using any approach that is available.
We will use our hooks to write information about our program’s execution path to afl’s shared memory segment. We can’t explicitly record the filename and line number of every line of code that is executed, because this would quickly get intractable for a program with thousands of files and millions of lines. Instead, when an “interesting” line of code runs (more on which below), we will increment a counter at a memory address given by a simple function of the current and previously recorded files and line numbers. The resulting bitmap can’t be mapped back into an exact execution path, but afl can still use it to notice and interpret differences in execution paths between different test cases.
We may get some collisions - two different lines of code that map to the same memory location and increment the same counter. But afl’s claim and bet is that as long as there aren’t too many of them, these collisions won’t materially impact its efficacy.
It may prove useful to even further reduce the amount of data that we send to afl. Writing to the shared memory takes CPU time, and writing too much data can flood the shared memory and make it hard for afl to extract any useful signals. There are at least two ways to deal with this. We can sample our instrumentation, and only report information for a random X% of executed lines. This is what afl does. Or, if your language provides the necessary tools, we can only write information for a subset of particularly interesting lines - for example, function calls or returns. This is what afl-ruby does.
It will be hard to rigorously verify that the interaction between your program and afl is exactly correct. Afl is not very amenable to unit testing. However, there are two heuristics you can use to convince yourself that your code is right. First, afl will yell at you if you try to fuzz something that doesn’t have any instrumentation. If afl is happy to start fuzzing your program then you must at least be writing something to the shared memory. And second, if your instrumentation is helpful to afl then you should be able to find a bug in a trivial example target much quicker than in QEMU (uninstrumented) mode.
Putting it all together
You should now have a working afl wrapper for your language. Try it out on a trivial test harness containing a simple bug, like the example in the afl-ruby README. You should see afl detect new execution paths and quickly find the crash. When you’re convinced that everything is working, point afl at the program that you originally wanted to fuzz (several hours and hundreds of lines of code ago). Whilst you’re waiting for afl to serve you up some bugs you can tidy up your wrapper code, write some docs, and push everything to GitHub or Bitbucket. If you have the momentum, look into and consider implementing ancillary afl tools like afl-cov, afl-cmin, and persistent mode.
You’re done. Congratulations!