"Stylish" is back, and you still shouldn't use it
16 Aug 2018
2 days after I published ‘“Stylish” browser extension steals all your internet history’, Stylish was pulled from the Chrome and Firefox stores. The story echoed around parts of the internet for a few days, my name was misspelled on several right-wing British news websites, and I felt that I’d helped make the world a fractionally better place. However, Stylish v3.1.8 is now back in the Firefox add-on store, and it’s bigger and better and more technically compliant than ever.
Will SimilarWeb (the adtech company that owns Stylish) try to sneak in more underhanded tracking in the future? I don’t see why not. Can we trust them? In my opinion, no. But thanks to the open source Stylish clone “Stylus”, these aren’t even questions that need to be answered. If you want to change the way that the internet looks, just use Stylus. It is functionally identical to Stylish, apart from the facts that it has never contained any spyware, and is not owned by a company that makes its money by selling your data.
To give a small amount of credit where a small amount of credit is due, Stylish v3.1.8 is more up front about its plans for tracking your entire online life. It comes with a tastefully designed startup screen asking whether you would like to opt-in to having all your browsing history sent to the SimilarWeb servers. If you tick the boxes saying “no, obviously not” then it also features an aesthetically pleasing design dark pattern designed to trick you into accidentally changing your mind.
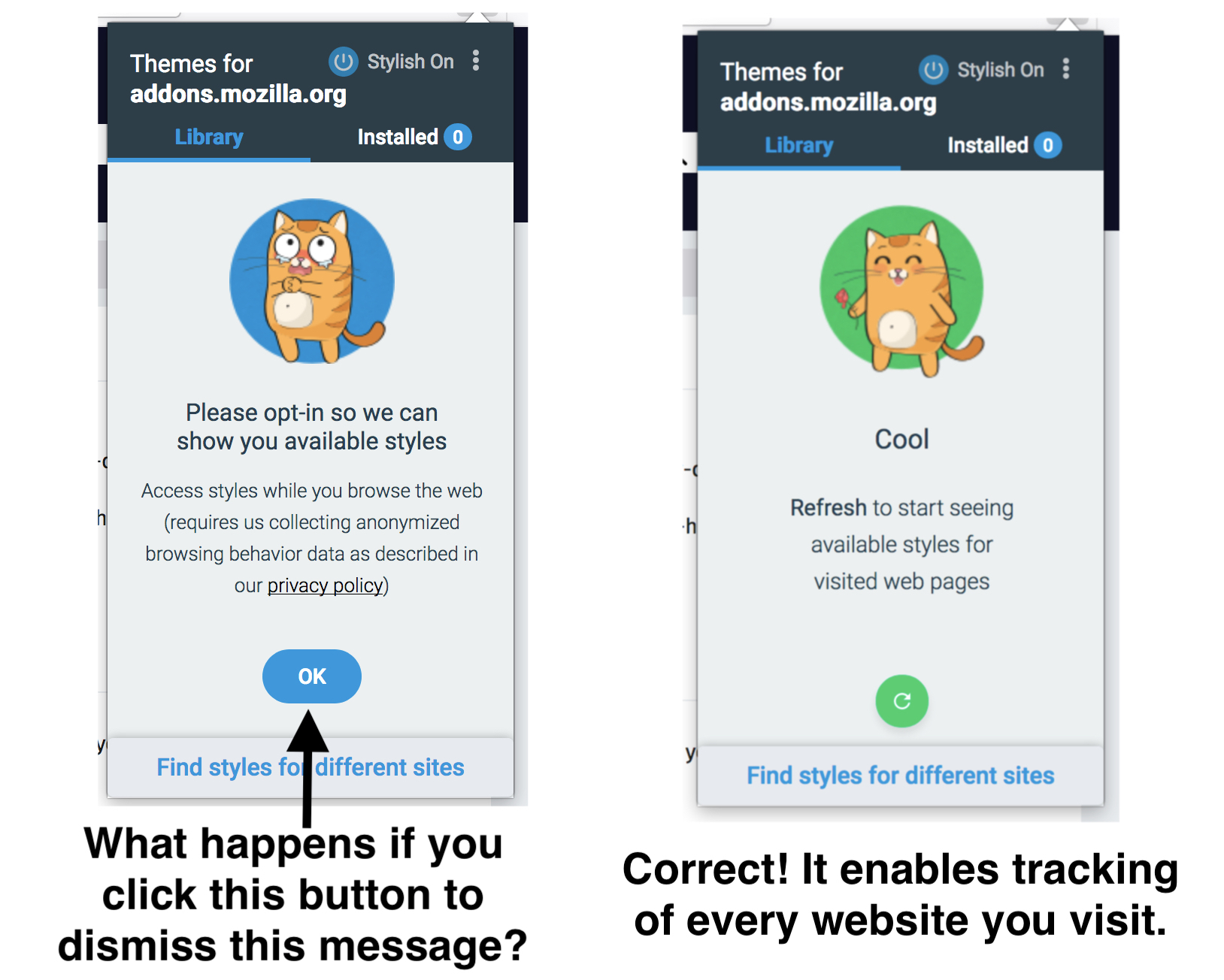
I suppose this is progress, but I can’t imagine that it will be making it into any TED talks any time soon.
Why is Stylish bothering to do this?
The v3.1.8 comeback is a bold play by the Stylish team. The Stylish Wikipedia page is written in the past tense and reads like an obituary. 8 of the top 10 Google results for “stylish extension” are articles with titles like “Google and Firefox pull the Stylish browser extension that tracked your every move”. The first 4 pages of Stylish’s reviews in the Firefox add-on store are all variations on the theme of “SPYWARE, DO NOT INSTALL”. But I suppose that SimilarWeb have nothing to lose, and as a B2B adtech company they have no reason to be concerned about public sentiment.
I’m surprised that SimilarWeb finds the personal browsing data that it siphons off via Stylish so valuable. The data almost certainly feeds into SimilarWeb’s main product, the SimilarWeb platform, a tool that provides reports on the aggregate usage statistics of websites and apps. For example, according to the SimilarWeb homepage, microsoftstore.com had 9.9MM visitors during October 2016, which put it 1,204th in some unspecified ranking of websites for the month. SimilarWeb produces these reports by combining Stylish data with data from a wide range of other sources, including Internet Service Providers, the public domain, and unspecified “Global Panels”. It then models, correlates, and extrapolates its insights from this amalgamated dataset.
I can see how buying data from enough large ISPs might allow you to draw conclusions about global internet usage patterns. Almost everyone uses an ISP, and so data collected from enough ISPs may plausibly be representative of the entire population. But data collected via Stylish will surely be riddled with so much sampling bias that it becomes worthless. The typical Stylish user is not the typical internet user, meaning that all that Stylish’s data can tell SimilarWeb is the average online browsing habits of the kind of person who uses Stylish. It would be foolish to conclude (and I’m certain that SimilarWeb does not) that since 80% of Stylish users visit Reddit at least once per day, 80% of the entire world must visit Reddit at least once per day too.
An analyst may be able to control for these kinds of biases, given enough additional demographic information about the people in the dataset. But if SimilarWeb does have access to this kind of information then either they have many, many more questions to answer, or the advance of adtech is even more virulent than I feared.
Nonetheless, SimilarWeb combines browsing data obtained from Stylish with data from all of its other sources. SimilarWeb describes this wide-net approach as “methodological pluralism”. However, it strikes me that combining thousands of bad datasets won’t ever give you a good dataset unless you know why the original ones are bad. A giant stew of miscellaneous, unattributed scraps of data can’t ever turn into a representative sample, no matter how much salt and machine learning you add.
Of course, I have only been thinking about this problem for the last 20 minutes. I’m sure that SimilarWeb have a lot of smart people working for them, and I’m sure that they’re all equipped with a lot of PhDs and Hadoop clusters. SimilarWeb has raised over $100MM in funding, several chunks of which have come from the British peer Lord Alliance of Manchester. My parents raised me to respect money and unelected politicians, and so I won’t conjecture any further.
Back in Style
The return of Stylish v3.1.8 to the Firefox add-on store could have been a neat illustration of the tradeoffs between privacy, utility and trust in untrustworthy corporations that we all face every day. For example, I know that Facebook plays fast and loose with my data, but now that I’ve untagged most of my photos and installed 4 layers of adblockers I currently consider this a price worth paying. I know that Diaspora and other federated social networks are out there too, but it would be disingenuous to claim that any of them are an exact substitute for Facebook. None of my friends are on Diaspora.
However, the Stylus browser extension is an exact substitute for Stylish. Stylus works with all of the same theme libraries as Stylish, looks almost identical, and even has a confusingly similar name. I cannot think of any conceivable reason to use any version of Stylish instead of Stylus. If you do still use Stylish, spend the 30 seconds to uninstall it and switch to Stylus. It will be the easiest piece of consumer activism you ever do.
2 days after I published ‘“Stylish” browser extension steals all your internet history’, Stylish was pulled from the Chrome and Firefox stores. The story echoed around parts of the internet for a few days, my name was misspelled on several right-wing British news websites, and I felt that I’d helped make the world a fractionally better place. However, Stylish v3.1.8 is now back in the Firefox add-on store, and it’s bigger and better and more technically compliant than ever.
Will SimilarWeb (the adtech company that owns Stylish) try to sneak in more underhanded tracking in the future? I don’t see why not. Can we trust them? In my opinion, no. But thanks to the open source Stylish clone “Stylus”, these aren’t even questions that need to be answered. If you want to change the way that the internet looks, just use Stylus. It is functionally identical to Stylish, apart from the facts that it has never contained any spyware, and is not owned by a company that makes its money by selling your data.
To give a small amount of credit where a small amount of credit is due, Stylish v3.1.8 is more up front about its plans for tracking your entire online life. It comes with a tastefully designed startup screen asking whether you would like to opt-in to having all your browsing history sent to the SimilarWeb servers. If you tick the boxes saying “no, obviously not” then it also features an aesthetically pleasing design dark pattern designed to trick you into accidentally changing your mind.
![]()
I suppose this is progress, but I can’t imagine that it will be making it into any TED talks any time soon.
Why is Stylish bothering to do this?
The v3.1.8 comeback is a bold play by the Stylish team. The Stylish Wikipedia page is written in the past tense and reads like an obituary. 8 of the top 10 Google results for “stylish extension” are articles with titles like “Google and Firefox pull the Stylish browser extension that tracked your every move”. The first 4 pages of Stylish’s reviews in the Firefox add-on store are all variations on the theme of “SPYWARE, DO NOT INSTALL”. But I suppose that SimilarWeb have nothing to lose, and as a B2B adtech company they have no reason to be concerned about public sentiment.
I’m surprised that SimilarWeb finds the personal browsing data that it siphons off via Stylish so valuable. The data almost certainly feeds into SimilarWeb’s main product, the SimilarWeb platform, a tool that provides reports on the aggregate usage statistics of websites and apps. For example, according to the SimilarWeb homepage, microsoftstore.com had 9.9MM visitors during October 2016, which put it 1,204th in some unspecified ranking of websites for the month. SimilarWeb produces these reports by combining Stylish data with data from a wide range of other sources, including Internet Service Providers, the public domain, and unspecified “Global Panels”. It then models, correlates, and extrapolates its insights from this amalgamated dataset.
I can see how buying data from enough large ISPs might allow you to draw conclusions about global internet usage patterns. Almost everyone uses an ISP, and so data collected from enough ISPs may plausibly be representative of the entire population. But data collected via Stylish will surely be riddled with so much sampling bias that it becomes worthless. The typical Stylish user is not the typical internet user, meaning that all that Stylish’s data can tell SimilarWeb is the average online browsing habits of the kind of person who uses Stylish. It would be foolish to conclude (and I’m certain that SimilarWeb does not) that since 80% of Stylish users visit Reddit at least once per day, 80% of the entire world must visit Reddit at least once per day too.
An analyst may be able to control for these kinds of biases, given enough additional demographic information about the people in the dataset. But if SimilarWeb does have access to this kind of information then either they have many, many more questions to answer, or the advance of adtech is even more virulent than I feared.
Nonetheless, SimilarWeb combines browsing data obtained from Stylish with data from all of its other sources. SimilarWeb describes this wide-net approach as “methodological pluralism”. However, it strikes me that combining thousands of bad datasets won’t ever give you a good dataset unless you know why the original ones are bad. A giant stew of miscellaneous, unattributed scraps of data can’t ever turn into a representative sample, no matter how much salt and machine learning you add.
Of course, I have only been thinking about this problem for the last 20 minutes. I’m sure that SimilarWeb have a lot of smart people working for them, and I’m sure that they’re all equipped with a lot of PhDs and Hadoop clusters. SimilarWeb has raised over $100MM in funding, several chunks of which have come from the British peer Lord Alliance of Manchester. My parents raised me to respect money and unelected politicians, and so I won’t conjecture any further.
Back in Style
The return of Stylish v3.1.8 to the Firefox add-on store could have been a neat illustration of the tradeoffs between privacy, utility and trust in untrustworthy corporations that we all face every day. For example, I know that Facebook plays fast and loose with my data, but now that I’ve untagged most of my photos and installed 4 layers of adblockers I currently consider this a price worth paying. I know that Diaspora and other federated social networks are out there too, but it would be disingenuous to claim that any of them are an exact substitute for Facebook. None of my friends are on Diaspora.
However, the Stylus browser extension is an exact substitute for Stylish. Stylus works with all of the same theme libraries as Stylish, looks almost identical, and even has a confusingly similar name. I cannot think of any conceivable reason to use any version of Stylish instead of Stylus. If you do still use Stylish, spend the 30 seconds to uninstall it and switch to Stylus. It will be the easiest piece of consumer activism you ever do.