Reliable osquery deployment for the paranoid
16 Feb 2021
Here’s the recording, transcript, and slides for a talk about gingerly deploying osquery to a server fleet that I gave at osquery@scale 2021.
Hi, my name is Rob Heaton and I’m a security engineer at Stripe on the Detection Infrastructure team.

My team is responsible for building the tools that security analysts use to detect and stop bad guys.
I’d like to start with a short story. Last year we started rolling out osquery to Stripe’s server fleet.
While we were designing our deployment we spoke to other teams within Stripe’s security organization, and we asked them if they had any thoughts. They went away and talked amongst themselves, and then came back and let us know that actually they very much did.

Our colleagues absolutely understood what we were trying to do. They acknowledged all the wonderful features of osquery that all of us here know and love, apart from those of you who are spies from Goaudit@Scale. However, the team pointed out that we were, in the nicest possible way, proposing to install a trojan on every server at Stripe. “This thing can exfiltrate almost any piece of data from the machines it runs on”, they pointed out. “Some of the scarier tables can remotely control servers.” “Yes,” we said, “isn’t it fantastic?”
Next we spoke to Stripe’s reliability team. We already run osquery on all our employee laptops. It’s been very useful, which is why we want to put it on our servers too. However, our laptop deployment has given us a mild PR problem with osquery. Some tasks cause osquery to get a little CPU hungry and cause people’s laptops to sound like they’re trying to fly to the moon.

We’ve tried to be responsive and tune our parameters, and we made a Slackbot to give guidance to people complaining about osqueryd. But people still get grumpy when their battery dies prematurely.
Anyway, the reliability team also absolutely understood what we were trying to do, but they had some concerns of their own. “Is osquery the thing on our laptops that…?” they started “Yes, but don’t worry, it’s perfectly safe.” we replied. “OK, well - this thing runs on every server at Stripe, including the mission-critical ones. It runs as root, performs a potentially large amount of work to grab a large amount of information, and you can update its configuration from a remote fleet manager that completely bypasses all of our normal change management infrastructure.”
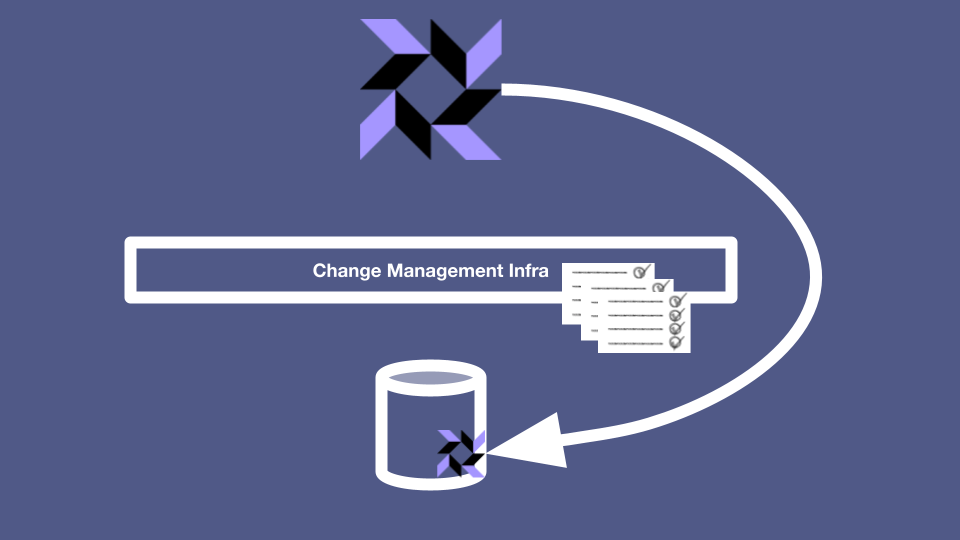
“Yes,” we said, “isn’t it fantastic?”
Mitigating these inconvenient but valid security and reliability concerns made my team’s lives a little more awkward for a few months. But I’m confident that the mitigations that we put in place will also make our lives much calmer and more stable for years to come. The stronger the safety guarantees you can give yourself, the faster you can move in the long-term, and just because you’re paranoid, that doesn’t mean you won’t cause a ruinous incident if you don’t take proper precautions.
Today I’m going to go into more detail about some of the safety considerations we contemplated when deploying osquery, and how we mitigated them. To be clear, all of the concerns that we’ll talk about today are solvable, given time and effort. Some of the concerns might not apply to your organization. Others might technically apply to you, but you might decide that you aren’t concerned about them. As always, it’s up to you to understand your own organization and to decide your own risk tolerance.
Let’s start by talking about the security of your osquery deployment

Osquery is an excellent security tool. But all tools expose attack surfaces, and security tools are no exception. Most osquery deployments consist, broadly, of 2 parts: the osquery agents that slurp up data from machines, and the fleet manager that these agents send their data to.
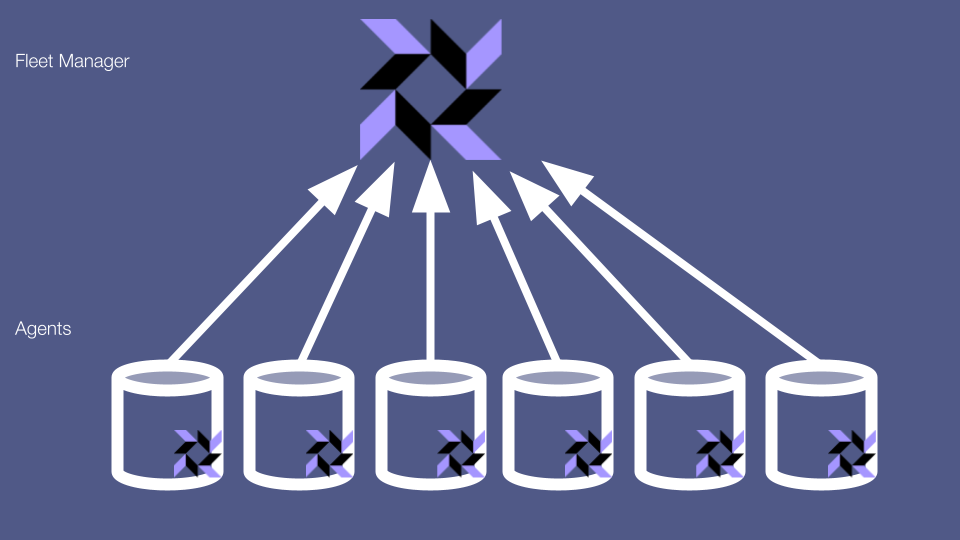
Let’s start with a boring but big concern about the fleet manager. You may be familiar with the principle of least privilege, which states that any system or component should only be able to access the data and resources necessary for it to carry out its job.

You don’t centralize data or privileges in one place, because this way you minimize the fallout if a component of your system gets compromised. Servers don’t have access to databases they don’t need; employees don’t have credentials that they don’t need; revolutionary fighters don’t know anything about other revolutionary fighters outside of their immediate revolutionary cell.
However, the whole point of the osquery fleet manager is that it centralizes a lot of important and sometimes sensitive information in a single place. This is what makes osquery so useful. But it also means that if the fleet manager is compromised then the attacker gets their hands on an incredible trove of data in a single stroke. Do you have secrets in your command-line arguments? SELECT * FROM processes will grab all of them.

What about in your environment variables? SELECT * FROM process_envs should do the job there.

OK but this is just reading data. At least the attacker can’t use osquery to pivot or directly mess with our servers, right? Wrong! In general, at least.
One very useful feature of osquery is the ability to run realtime queries on a host. Instead of relying on the potentially stale data that the host periodically pushes to the fleet manager, you can use the fleet manager to run queries directly on the host.

These queries look like SQL, and indeed osquery uses the SQLite engine to evaluate them. However, osquery doesn’t actually use SQLite for data storage. Instead, much of the data in these realtime queries is generated on-the-fly by reading it directly from the system. On Linux, if you run SELECT * FROM processes then the osquery agent retrieves data about running processes by reading the /proc filesystem.
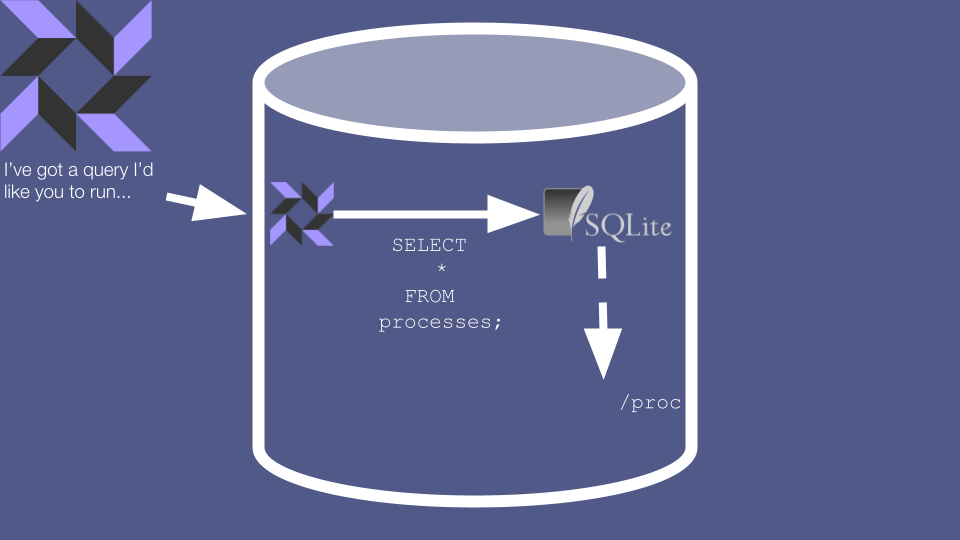
Why does this matter? Well, several of these “Virtual Tables” aren’t used for retrieving data at all. Instead, they’re used as a quirky command line interface for telling the agent to execute a full-on command. For example, SELECT-ing from the curl table actually causes a real-life HTTP request to be issued, and the results to be returned to the caller.
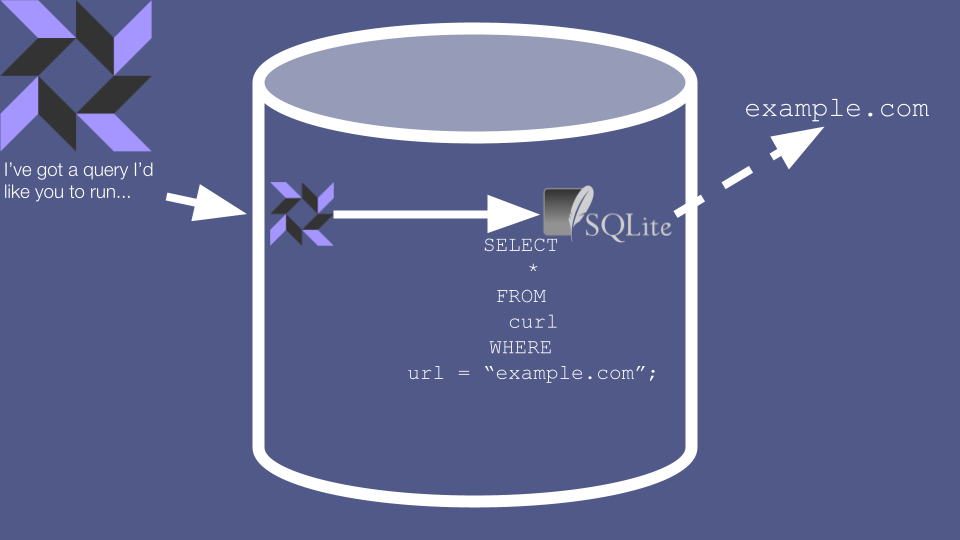
This means that a compromise of the fleet manager doesn’t just mean that the attacker gets read access to sensitive data - they can also use realtime queries to manipulate the server. For example, the attacker could use the curl table to send an HTTP request to any internal service that their target server has access to.
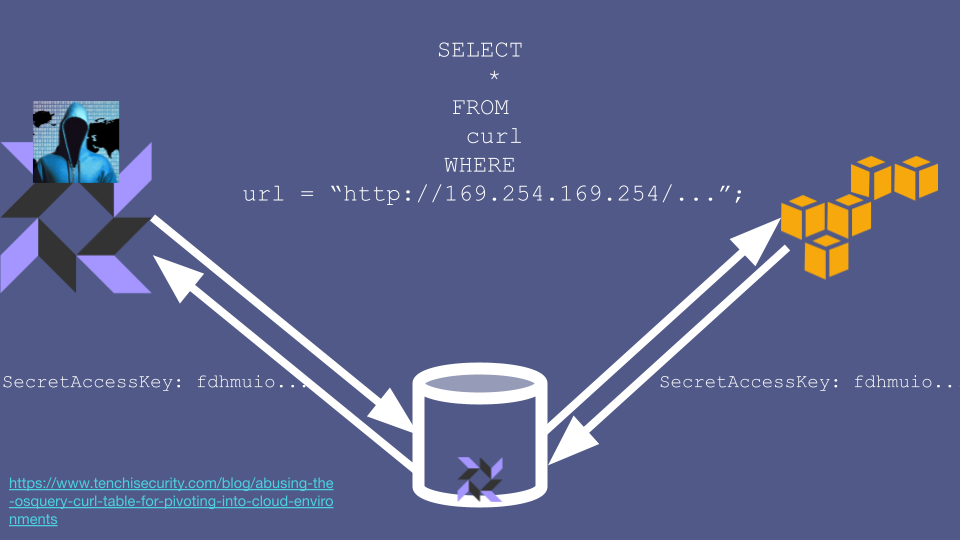
In an AWS environment, one particularly interesting service for an attacker to target is the AWS metadata service. One of the jobs of the metadata service is to dish out temporary credentials to allow servers to assume different roles.

The attacker could therefore ask the metadata service for a set of temporary credentials, and read them out of the response returned by the metadata service. Some of these credentials will work from the public internet, so the attacker can use them from the comfort of their own home to, for example, exfiltrate all your data from S3.
When I was practicing this talk an imaginary heckler yelled “but Rob, you can just use your osquery config to disable these power features!”

True enough, but thanks for setting me up for my next point, imaginary heckler. You can certainly configure your osquery agents, and you can certainly use this config to disable features and tables. But that’s not the full story.
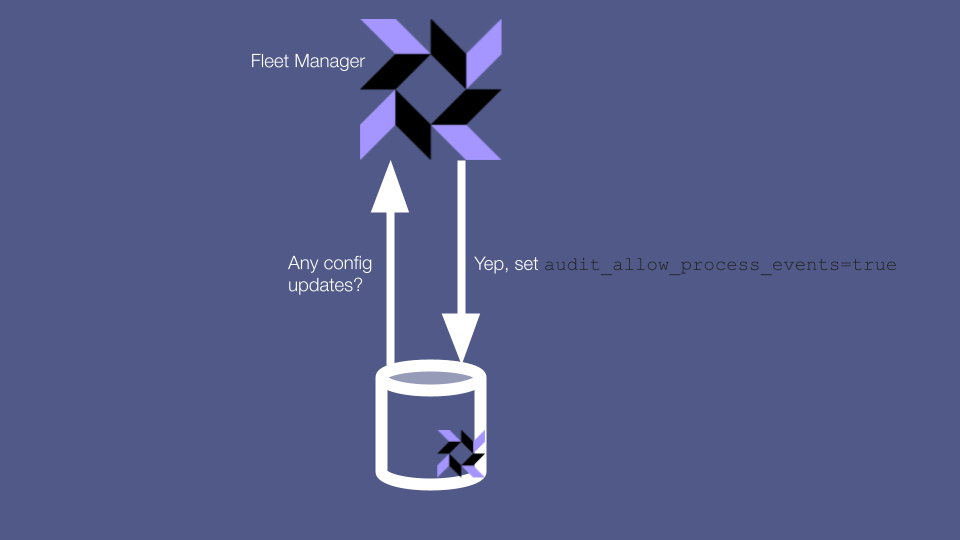
One common and convenient way to manage osquery configuration is to set your config via your centralized fleet manager, and have clients pull down their config from there. However, this approach means that if an attacker has access to your fleet manager then they can update your config to re-enable all the powerful tables that they need in order to go about their devious work.

You can reduce your attack surface area by restricting which user accounts have permission to update agent configs, but since someone has to be able to update your config, you can’t lock this attack vector down completely.
How about another, more scorched earth attack?

First, the attacker updates the osquery config to disable the watchdog that kills the agent if it consumes too much CPU. Second, the attacker creates ten thousand scheduled queries that hammer the most computationally expensive tables available. Finally, the turn on File Integrity Monitoring on every file on every host. This should be enough to cause some extreme inconvenience for your entire fleet
The cast iron, if awkward, mitigation is to not configure your osquery agents via the fleet manager, but to instead do it using good old-fashioned config files stored on your servers’ disks. If you use config files then an attacker with access to the fleet manager can’t re-enable scary tables because the agent doesn’t listen to the fleet manager anymore.

However, you’ll have to manage this config file using a separate tool like puppet, and updating it will take much more effort than a click in a nice UI.
These are some of the security concerns that you should consider when designing an osquery deployment. However, when you’re operating at scale it’s arguably just as likely that you break your own systems as a baddie breaks them for you. So let’s talk about reliability.

Reliability
Osquery does a lot of work. Sometimes in order to do this work it needs a lot of memory and, especially, CPU. Remember all the grumbling about osquery on my colleagues’ laptops.

This means that if you’re on whatever your organization calls your version of my team, you’re going to be responsible for running a complex agent on possibly every host in your organization’s fleet. This means that you’d better make sure that you’ve configured your agent properly and added safeguards and response tools in case of emergency. A 0.01% failure rate of a massive number is still a pretty big number.
The first line of reliability defence is osquery’s own watchdog.
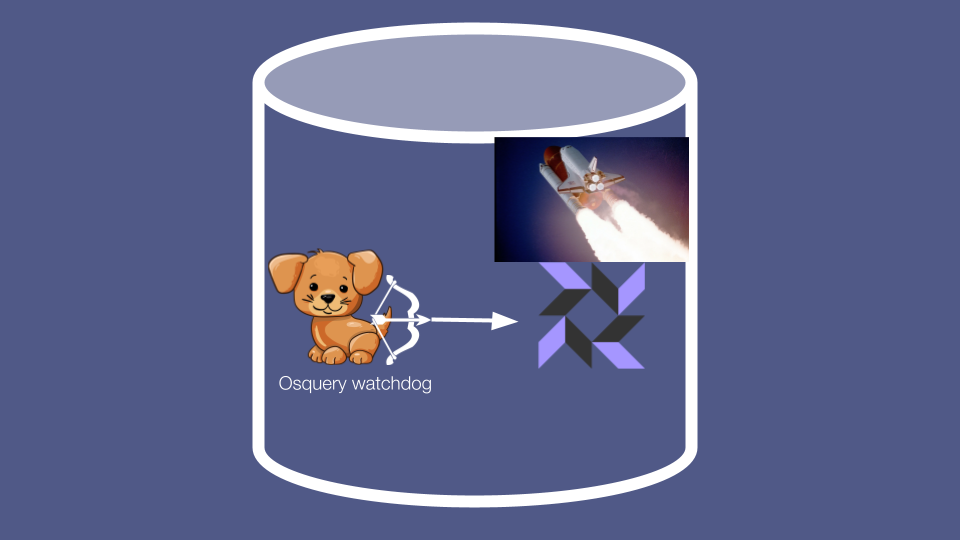
This is a process that watches the main osqueryd agent process. When the agent consumes more than a threshold amount of resources for a threshold period of time (eg. 30% CPU for 20 seconds), the watchdog kills the agent and denylists the scheduled query that caused the resource hogging for the next 24 hours.
This is a great start, and you might reasonably decide that this is enough for you. Just make sure that you record when the watchdog shoots a worker and possibly alert when the rate of murders exceeds a threshold so that you can investigate.
If you’re paranoid then you might want to add extra lines of defence, for example Linux cgroups.

Cgroups allow you to tell the operating system to only allow a process to consume a threshold level of CPU or other system resources. This is a hard, OS-level constraint that will catch you if your watchdog ever falls asleep or you misconfigure it.
Whatever approaches you take, you should apply generic good engineering principles.

Before your original rollout, game day your systems by inducing failures. Schedule thousands of scheduled queries that cause osqueryd to go nuts; see if your watchdog does what you expect when you do this, see how your systems respond. You can’t reasonably hope to gameday osquery’s interactions with every service at your organization, so you’ll also need to run a gradual rollout, with clear metrics and pre-defined, pre-tested rollback procedures and runbooks.
Even once your osquery deployment is up and running, the fun has only just started. You’ll need to maintain it and will want to update it. How will you make sure that any new scheduled queries are safe and don’t consume too many resources?

How are you going to distribute the agent binary to new machines?

On the one hand you want to bake it as deep as possible into your machines, maybe into your base image, so that osquery starts collecting data as soon as a machine starts up and starts bootstrapping. This will enable you to catch bad guys messing with your bootstrapping process. On the other hand, baking the agent into your base image will make updating the agent more difficult, since you can’t just distribute an updated agent; you also have to update your base images.

How will you deploy changes to your osquery config?
Recall our earlier discussions of the tradeoffs between convenience and safety. Using the fleet manager is very convenient, but it also gives you a backdoor change management process, separate from everything else your organization does and that only applies to osquery.
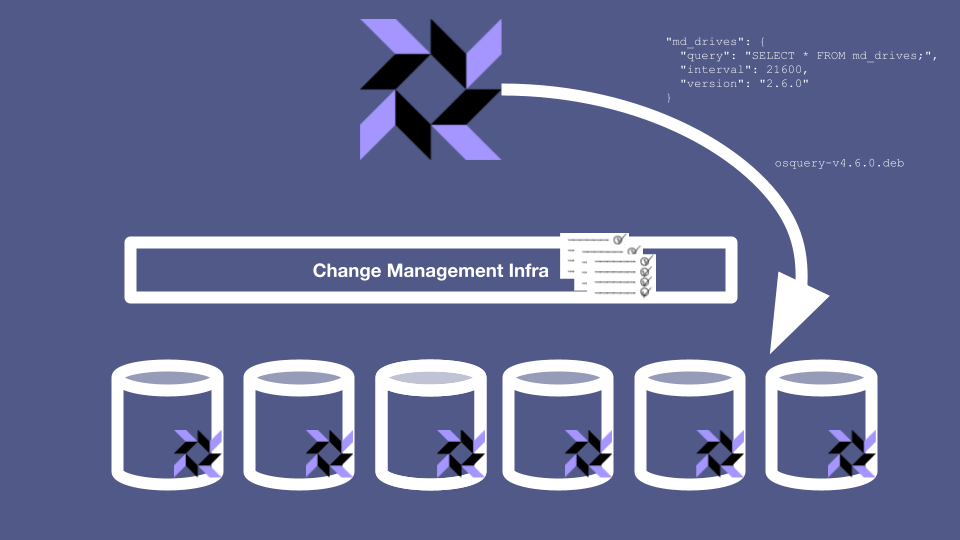
Suppose that your organization is in the middle of a code freeze or a giant incident. All normal deploys have been locked in order to make sure that no one inadvertently causes any instability in the system. But since you have your own deploy path that deploy locks don’t apply to, you don’t have any guard rails keeping you from doing anything problematic. This could cause some difficulties. Whether this is a showstopper or a shoulder-shrug depends on your organization’s risk-modeling. Either way, you should at least make sure that any fleet manager-driven updates get noted in a durable papertrail somewhere.
As I said at the start, these are all solvable, answerable questions.

You should just make sure to answer them ahead of time so you don’t have to answer them at 3am when your fleet is compromised or on fire. Understand your own threat models - they’ll be different to mine and different to those of the person virtually sitting next to you. It’s OK to decide to accept risks in return for a faster or simpler system. But if you’re feeling paranoid, then please do get in touch, I’d love to talk more.
Here’s the recording, transcript, and slides for a talk about gingerly deploying osquery to a server fleet that I gave at osquery@scale 2021.
Hi, my name is Rob Heaton and I’m a security engineer at Stripe on the Detection Infrastructure team.
My team is responsible for building the tools that security analysts use to detect and stop bad guys.
I’d like to start with a short story. Last year we started rolling out osquery to Stripe’s server fleet.
While we were designing our deployment we spoke to other teams within Stripe’s security organization, and we asked them if they had any thoughts. They went away and talked amongst themselves, and then came back and let us know that actually they very much did.
Our colleagues absolutely understood what we were trying to do. They acknowledged all the wonderful features of osquery that all of us here know and love, apart from those of you who are spies from Goaudit@Scale. However, the team pointed out that we were, in the nicest possible way, proposing to install a trojan on every server at Stripe. “This thing can exfiltrate almost any piece of data from the machines it runs on”, they pointed out. “Some of the scarier tables can remotely control servers.” “Yes,” we said, “isn’t it fantastic?”
Next we spoke to Stripe’s reliability team. We already run osquery on all our employee laptops. It’s been very useful, which is why we want to put it on our servers too. However, our laptop deployment has given us a mild PR problem with osquery. Some tasks cause osquery to get a little CPU hungry and cause people’s laptops to sound like they’re trying to fly to the moon.
We’ve tried to be responsive and tune our parameters, and we made a Slackbot to give guidance to people complaining about osqueryd. But people still get grumpy when their battery dies prematurely.
Anyway, the reliability team also absolutely understood what we were trying to do, but they had some concerns of their own. “Is osquery the thing on our laptops that…?” they started “Yes, but don’t worry, it’s perfectly safe.” we replied. “OK, well - this thing runs on every server at Stripe, including the mission-critical ones. It runs as root, performs a potentially large amount of work to grab a large amount of information, and you can update its configuration from a remote fleet manager that completely bypasses all of our normal change management infrastructure.”
“Yes,” we said, “isn’t it fantastic?”
Mitigating these inconvenient but valid security and reliability concerns made my team’s lives a little more awkward for a few months. But I’m confident that the mitigations that we put in place will also make our lives much calmer and more stable for years to come. The stronger the safety guarantees you can give yourself, the faster you can move in the long-term, and just because you’re paranoid, that doesn’t mean you won’t cause a ruinous incident if you don’t take proper precautions.
Today I’m going to go into more detail about some of the safety considerations we contemplated when deploying osquery, and how we mitigated them. To be clear, all of the concerns that we’ll talk about today are solvable, given time and effort. Some of the concerns might not apply to your organization. Others might technically apply to you, but you might decide that you aren’t concerned about them. As always, it’s up to you to understand your own organization and to decide your own risk tolerance.
Let’s start by talking about the security of your osquery deployment
Osquery is an excellent security tool. But all tools expose attack surfaces, and security tools are no exception. Most osquery deployments consist, broadly, of 2 parts: the osquery agents that slurp up data from machines, and the fleet manager that these agents send their data to.
Let’s start with a boring but big concern about the fleet manager. You may be familiar with the principle of least privilege, which states that any system or component should only be able to access the data and resources necessary for it to carry out its job.
You don’t centralize data or privileges in one place, because this way you minimize the fallout if a component of your system gets compromised. Servers don’t have access to databases they don’t need; employees don’t have credentials that they don’t need; revolutionary fighters don’t know anything about other revolutionary fighters outside of their immediate revolutionary cell.
However, the whole point of the osquery fleet manager is that it centralizes a lot of important and sometimes sensitive information in a single place. This is what makes osquery so useful. But it also means that if the fleet manager is compromised then the attacker gets their hands on an incredible trove of data in a single stroke. Do you have secrets in your command-line arguments? SELECT * FROM processes will grab all of them.
What about in your environment variables? SELECT * FROM process_envs should do the job there.
OK but this is just reading data. At least the attacker can’t use osquery to pivot or directly mess with our servers, right? Wrong! In general, at least.
One very useful feature of osquery is the ability to run realtime queries on a host. Instead of relying on the potentially stale data that the host periodically pushes to the fleet manager, you can use the fleet manager to run queries directly on the host.
These queries look like SQL, and indeed osquery uses the SQLite engine to evaluate them. However, osquery doesn’t actually use SQLite for data storage. Instead, much of the data in these realtime queries is generated on-the-fly by reading it directly from the system. On Linux, if you run SELECT * FROM processes then the osquery agent retrieves data about running processes by reading the /proc filesystem.
Why does this matter? Well, several of these “Virtual Tables” aren’t used for retrieving data at all. Instead, they’re used as a quirky command line interface for telling the agent to execute a full-on command. For example, SELECT-ing from the curl table actually causes a real-life HTTP request to be issued, and the results to be returned to the caller.
This means that a compromise of the fleet manager doesn’t just mean that the attacker gets read access to sensitive data - they can also use realtime queries to manipulate the server. For example, the attacker could use the curl table to send an HTTP request to any internal service that their target server has access to.
In an AWS environment, one particularly interesting service for an attacker to target is the AWS metadata service. One of the jobs of the metadata service is to dish out temporary credentials to allow servers to assume different roles.
The attacker could therefore ask the metadata service for a set of temporary credentials, and read them out of the response returned by the metadata service. Some of these credentials will work from the public internet, so the attacker can use them from the comfort of their own home to, for example, exfiltrate all your data from S3.
When I was practicing this talk an imaginary heckler yelled “but Rob, you can just use your osquery config to disable these power features!”
True enough, but thanks for setting me up for my next point, imaginary heckler. You can certainly configure your osquery agents, and you can certainly use this config to disable features and tables. But that’s not the full story.
One common and convenient way to manage osquery configuration is to set your config via your centralized fleet manager, and have clients pull down their config from there. However, this approach means that if an attacker has access to your fleet manager then they can update your config to re-enable all the powerful tables that they need in order to go about their devious work.
You can reduce your attack surface area by restricting which user accounts have permission to update agent configs, but since someone has to be able to update your config, you can’t lock this attack vector down completely.
How about another, more scorched earth attack?
First, the attacker updates the osquery config to disable the watchdog that kills the agent if it consumes too much CPU. Second, the attacker creates ten thousand scheduled queries that hammer the most computationally expensive tables available. Finally, the turn on File Integrity Monitoring on every file on every host. This should be enough to cause some extreme inconvenience for your entire fleet
The cast iron, if awkward, mitigation is to not configure your osquery agents via the fleet manager, but to instead do it using good old-fashioned config files stored on your servers’ disks. If you use config files then an attacker with access to the fleet manager can’t re-enable scary tables because the agent doesn’t listen to the fleet manager anymore.
However, you’ll have to manage this config file using a separate tool like puppet, and updating it will take much more effort than a click in a nice UI.
These are some of the security concerns that you should consider when designing an osquery deployment. However, when you’re operating at scale it’s arguably just as likely that you break your own systems as a baddie breaks them for you. So let’s talk about reliability.
Reliability
Osquery does a lot of work. Sometimes in order to do this work it needs a lot of memory and, especially, CPU. Remember all the grumbling about osquery on my colleagues’ laptops.
This means that if you’re on whatever your organization calls your version of my team, you’re going to be responsible for running a complex agent on possibly every host in your organization’s fleet. This means that you’d better make sure that you’ve configured your agent properly and added safeguards and response tools in case of emergency. A 0.01% failure rate of a massive number is still a pretty big number.
The first line of reliability defence is osquery’s own watchdog.
This is a process that watches the main osqueryd agent process. When the agent consumes more than a threshold amount of resources for a threshold period of time (eg. 30% CPU for 20 seconds), the watchdog kills the agent and denylists the scheduled query that caused the resource hogging for the next 24 hours.
This is a great start, and you might reasonably decide that this is enough for you. Just make sure that you record when the watchdog shoots a worker and possibly alert when the rate of murders exceeds a threshold so that you can investigate.
If you’re paranoid then you might want to add extra lines of defence, for example Linux cgroups.
Cgroups allow you to tell the operating system to only allow a process to consume a threshold level of CPU or other system resources. This is a hard, OS-level constraint that will catch you if your watchdog ever falls asleep or you misconfigure it.
Whatever approaches you take, you should apply generic good engineering principles.
Before your original rollout, game day your systems by inducing failures. Schedule thousands of scheduled queries that cause osqueryd to go nuts; see if your watchdog does what you expect when you do this, see how your systems respond. You can’t reasonably hope to gameday osquery’s interactions with every service at your organization, so you’ll also need to run a gradual rollout, with clear metrics and pre-defined, pre-tested rollback procedures and runbooks.
Even once your osquery deployment is up and running, the fun has only just started. You’ll need to maintain it and will want to update it. How will you make sure that any new scheduled queries are safe and don’t consume too many resources?
How are you going to distribute the agent binary to new machines?
On the one hand you want to bake it as deep as possible into your machines, maybe into your base image, so that osquery starts collecting data as soon as a machine starts up and starts bootstrapping. This will enable you to catch bad guys messing with your bootstrapping process. On the other hand, baking the agent into your base image will make updating the agent more difficult, since you can’t just distribute an updated agent; you also have to update your base images.
How will you deploy changes to your osquery config?
Recall our earlier discussions of the tradeoffs between convenience and safety. Using the fleet manager is very convenient, but it also gives you a backdoor change management process, separate from everything else your organization does and that only applies to osquery.
Suppose that your organization is in the middle of a code freeze or a giant incident. All normal deploys have been locked in order to make sure that no one inadvertently causes any instability in the system. But since you have your own deploy path that deploy locks don’t apply to, you don’t have any guard rails keeping you from doing anything problematic. This could cause some difficulties. Whether this is a showstopper or a shoulder-shrug depends on your organization’s risk-modeling. Either way, you should at least make sure that any fleet manager-driven updates get noted in a durable papertrail somewhere.
As I said at the start, these are all solvable, answerable questions.
You should just make sure to answer them ahead of time so you don’t have to answer them at 3am when your fleet is compromised or on fire. Understand your own threat models - they’ll be different to mine and different to those of the person virtually sitting next to you. It’s OK to decide to accept risks in return for a faster or simpler system. But if you’re feeling paranoid, then please do get in touch, I’d love to talk more.